Forget AWS Textract. Forget Google DocAI.
KraftLens is the revolutionary new engine that
truly understands document structure,
delivering accuracy the giants can't match.
The New Standard in Document AI.

The $50B Trapped Data Problem
80% of enterprise data is locked in unstructured documents. Invoices, contracts, medical records—all sitting in PDFs, inaccessible to your AI systems.
The Cost of Inaction:
- Manual Entry Errors (1-4% error rate)
- Slow Turnaround Time (Days vs Seconds)
- Compliance Risks & Lost Revenue
80%
of business data is
unstructured.
60%
time saved vs
manual entry.
Traditional OCR gets the words but misses the structure. You're left with garbage data. KraftLens changes that.

Who Uses KraftLens?
Real teams. Real results. Real ROI.
Revolutionary Technology. Unmatched Precision.
We didn't just wrap an API. We rebuilt document understanding from the ground up using proprietary layout-aware LLMs. The result? A quantum leap in accuracy for complex financial and legal documents.
99%
Accuracy GuaranteedOn complex tables and
structured documents

Ready to Transform Your Documents?
Book a DemoTwo Powerful Workflows
Upload Document
Upload your PDF or image document to get started
Define Fields
Add your field list and specify page numbers for extraction
Get Results
Receive structured data extracted with 99% accuracy
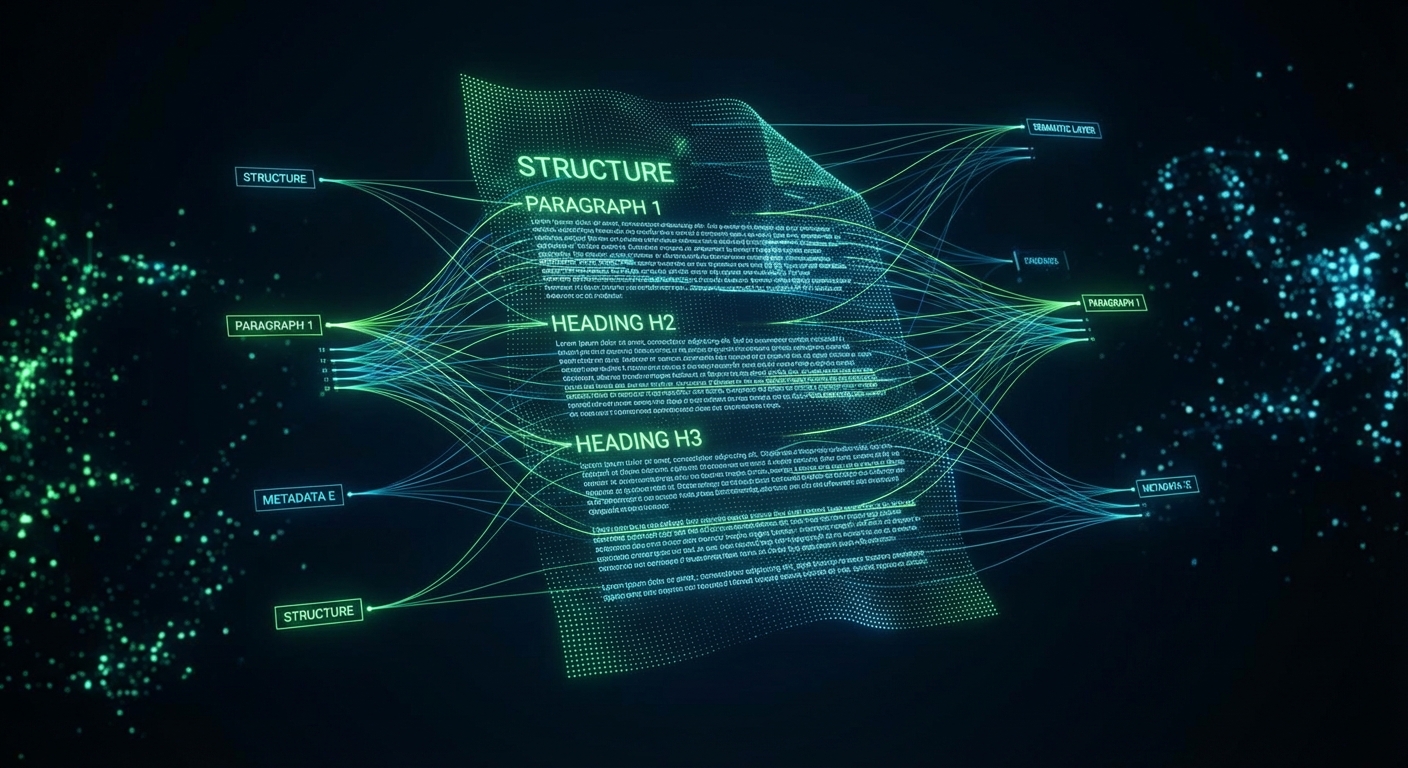
Proprietary Layout-Cognition System
Our architecture uses a multi-stage pipeline to decompose, analyze, and reconstruct document structures with pixel-perfect accuracy. Unlike standard OCR, we understand the relationship between elements.

We specialize in delivering high-accuracy data extraction, unparalleled security, and seamless integration.
Why We Win
Superior
Accuracy.
We consistently outperform legacy OCR providers on complex tables and handwriting.
Security
Native
Your data security is paramount. We offer SOC2 compliance and on-premise deployment options.
Developer
Centric
Built by developers for developers. Our APIs are easy to integrate, well-documented, and robust.
Our Journey
Inception
Research begins on multi-modal document understanding.
Breakthrough
First prototype outperforms AWS Textract on complex tables.
Enterprise Pilot
Launched first enterprise deployment. Processing 100K+ pages monthly.
Public Launch
SOC2 Compliance achieved. Platform open to public.
| Model | mAP@[.50:.95] | AP50 | AP75 | Latency (sec/page) | Performance Grade |
|---|---|---|---|---|---|
| Table Detection | 0.834 | 1.000 | 0.976 | 0.139 | ⭐⭐⭐⭐⭐ Excellent |
| Column Detection | 0.714 | 0.973 | 0.849 | 0.110 | ⭐⭐⭐⭐ Very Good |
| Header Detection | 0.605 | 0.925 | 0.692 | 0.108 | ⭐⭐⭐ Good |
Technical Performance Metrics
Our proprietary models achieve excellent performance across all detection tasks with minimal latency. Table detection shows exceptional accuracy with AP50 of 1.000, while maintaining sub-150ms processing time per page. These metrics represent Phase 1 benchmark results from our comprehensive evaluation framework.